HCIP学习笔记 数据库服务规划(五)—— 数据处理服务
在HCIP(华为认证ICT专家)的学习体系中,数据库服务规划是构建高效、稳定数据平台的核心环节。本部分聚焦于“数据处理服务”,旨在解析如何通过合理规划与配置,确保数据在应用系统中的有效流动、转换与价值提炼。
一、数据处理服务的核心定位
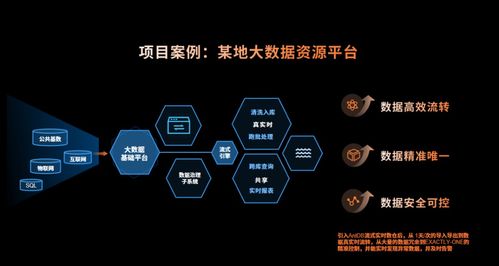
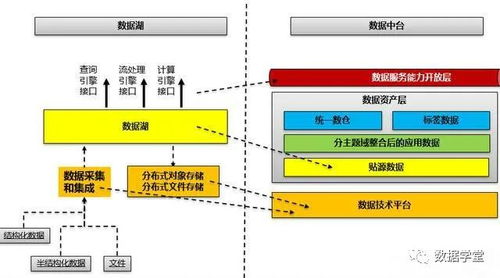
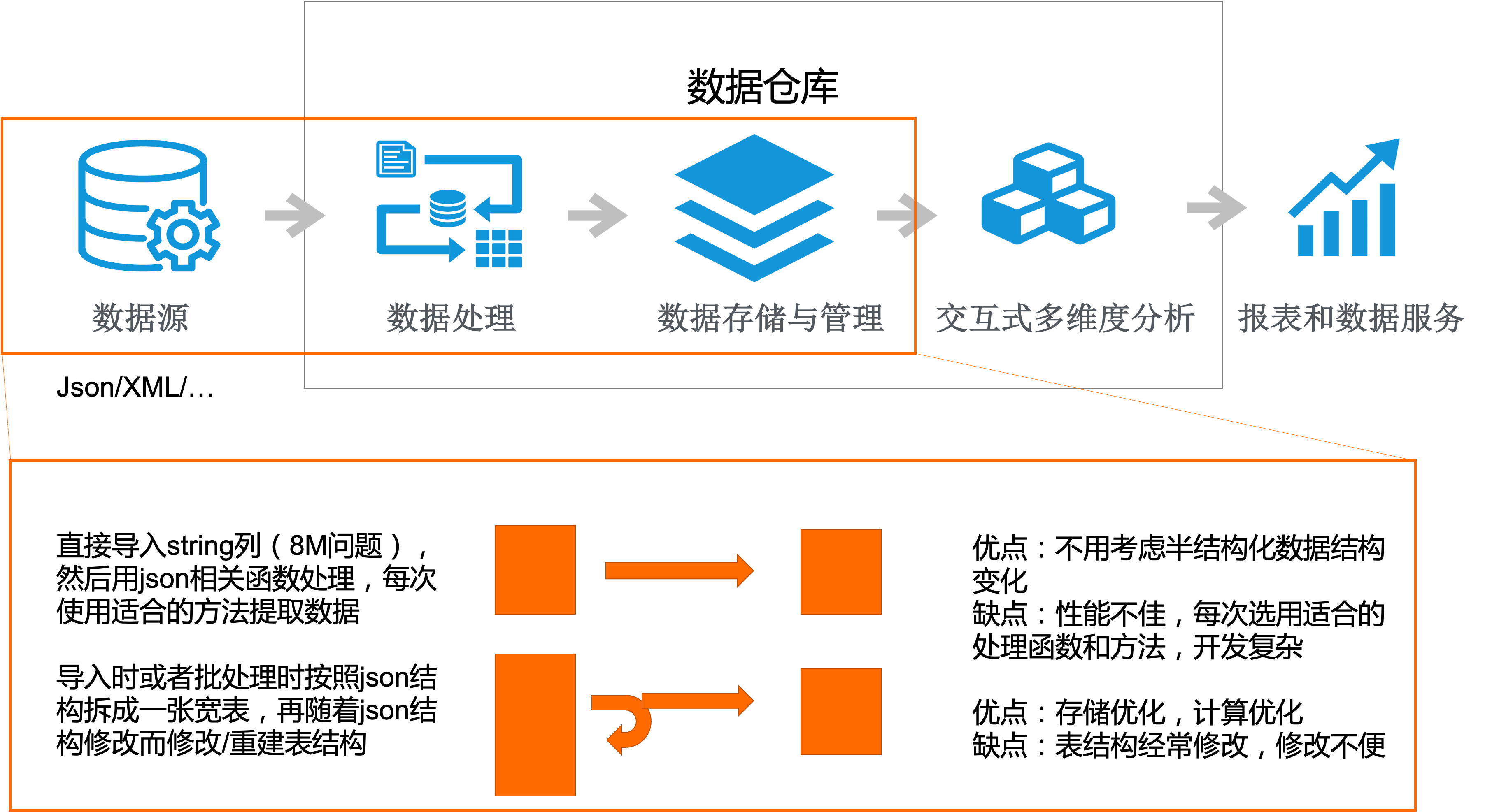
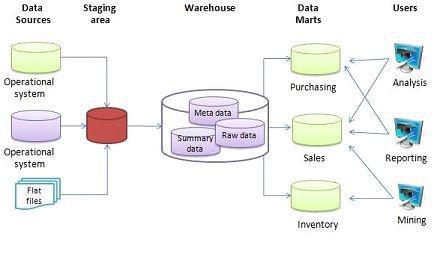
数据处理服务是数据库架构中承上启下的关键层。它主要负责对来自数据源(如业务数据库、日志文件、外部API等)的原始数据进行抽取、转换、加载(ETL),或进行实时流处理,最终将规整、可用的数据提供给数据仓库、数据湖或直接服务于分析应用与报表系统。其规划质量直接决定了数据的时效性、一致性与可用性。
二、关键规划维度
- 处理模式选择:
- 批处理:适用于对时效性要求不高、数据量大的周期性处理任务,如日终报表生成、历史数据迁移。规划时需重点考虑作业调度、资源隔离与错误重试机制。
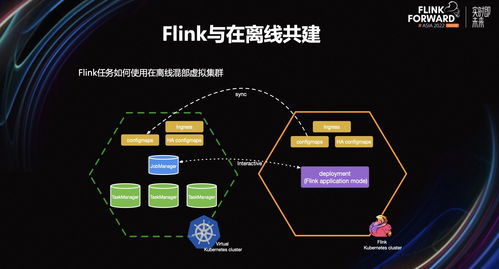
- 流处理:适用于实时监控、实时推荐等对低延迟有极高要求的场景。规划核心在于选择高吞吐、低延迟的流处理框架(如Flink, Spark Streaming),并设计合理的窗口与状态管理策略。
- Lambda/Kappa架构:对于需要同时满足批处理准确性与流处理实时性的复杂场景,需规划混合架构,明确批处理层与速度层的职责与数据合并逻辑。
- 服务组件与技术选型:
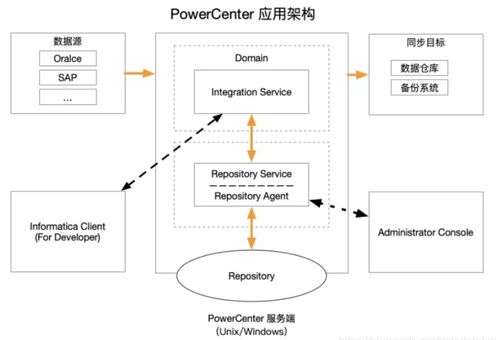
- ETL/ELT工具:根据团队技能与数据规模,选择商用工具(如DataStage, Informatica)或开源框架(如Apache NiFi, Talend)。规划需评估其对接数据源的能力、转换功能的丰富度以及运维复杂度。
- 计算引擎:针对大规模数据处理,需规划分布式计算引擎(如Spark, Hive on MR/Tez)的集群规模、资源队列划分与优化参数。
- 实时计算引擎:如Flink,规划其集群高可用配置、Checkpoint机制与反压处理策略,确保实时任务的稳定运行。
- 数据流水线与作业调度:
- 设计清晰、模块化的数据处理流水线(DAG),明确各环节的输入输出与依赖关系。
- 规划集中式的作业调度系统(如Airflow, DolphinScheduler),实现任务依赖管理、监控告警与失败自动恢复,提升运维自动化水平。
- 数据质量与监控:
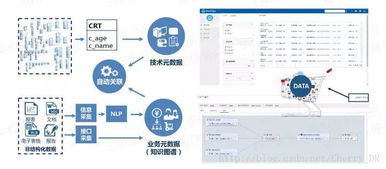
- 在数据处理各环节嵌入数据质量校验规则(如完整性、一致性、唯一性检查)。
- 规划全面的监控体系,涵盖作业执行状态、处理延迟、资源利用率及数据质量指标,并设置阈值告警,实现问题快速定位。
- 资源与性能规划:
- 根据数据量、处理频率和SLA要求,预估计算、存储与网络资源需求。
- 规划性能优化策略,包括数据分区、索引优化、计算下推、中间结果缓存等,确保数据处理效率满足业务需求。
三、规划实践要点与挑战
- 要点:始终以业务需求为驱动,平衡性能、成本与复杂度;设计具备弹性和可扩展性的架构以应对未来数据增长;高度重视数据血缘与元数据管理,保障数据处理过程的可追溯性。
- 挑战:处理多样化的数据源与异构数据格式;保障实时处理场景下的端到端低延迟与精确一次(Exactly-Once)语义;在资源有限的情况下实现批流任务的混合部署与资源隔离。
###
数据处理服务的规划是数据库服务从“存储”走向“应用”的桥梁。一个精心规划的数据处理层,能够将原始数据高效、可靠地转化为驱动业务洞察与决策的优质资产,是构建现代数据中台与智能分析能力不可或缺的基石。在HCIP的实践中,需结合具体业务场景,灵活运用上述原则,设计出健壮、高效的数据处理解决方案。
如若转载,请注明出处:http://www.zhiqiangbufa.com/product/49.html
更新时间:2026-06-19 19:56:20